 Menu
Menu
今天要介绍的这篇文章的作者是Ben Goldacre,他和Jonathan Gray最近在期刊Trails上发表了一篇文章来介绍他们的新研究项目。OpenTrials到底是什么呢,请看正文。
我们最近在期刊Trials上发表了一篇我们正在研究的论文。这个想法很有抱负,但也姗姗来迟。OpenTrials,一个对所有临床试验数据、相关文件开放,无门槛索引的项目。
“乌烟瘴气”的临床试验
你可能很惊讶,类似于这样的项目怎会没有先例。但是临床试验的世界真的是有点混乱,当触及到知识管理的层面中,人们也渐渐意识到了此类问题。
整个试验照例不出版,以免在医学文献中受歧视和被夸大。当试验出版了,在学术期刊文章中就会被错误的引用。
你可以发现相同的试验在不同的情况下有不一样的结果,而在期刊论文中的信息相比其他临床试验报告也不够全面。
而且,像Case Report Forms and Ethics Committee 这种比较有用的文献也并非触手可得,即使我们知道他们会包含非常重要的信息。
所有试验的数据全汇总
这就是我们为什么要建立一个对所有可公开的试验文件、数据的集合平台,这个平台可以进行数据存储和链接,并且对于用户来说也没有门槛。
这并不是一个新颖的想法。此类需求之前就有谈论过,像1999年由Doug Altman和lain Chalmers建立的“threaded publications”项目,以及近期的“Linked Reports of Clinical Trials”,都是让出版商在CrossMark上建立一个试验ID的唯一号,这样所有关于此试验的出版物就可以查出来。
我们所做的远远不止这些,致力于汇聚所有种类信息的集合,通过试验去勾连他们。如下图↓
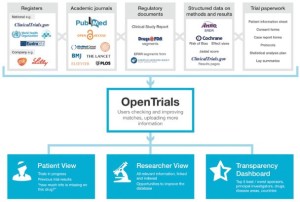
将所有的信息放在一个平台上有两个好处。首先,它帮助人们找到有用的东西从而做出正确的决定,尤其是医生、研究者和病人。
将所有的信息存储在一个地方有可以直截了当的做很多事情,具体可以参见我们论文中“Use Cases”这个部分的详细说明。
然而,我们也希望它产生一定的文化影响,当你看到一些试验所有重要的文件都可以公开使用,这样就会提升你的心里预期,特别是针对一些资料尚缺的试验。
因为这个想法比较有“野心”,所以在此很值得讲讲它是怎样建立起来的。建立一个完美的,手动存储成千上万试验信息的数据库需要消耗大量的资金。同样的,仅仅建立一个空的数据库然后邀请人们加入是没有必要的。
三步法
所以我们用三种方式让这个数据库渐渐丰富起来。首先,我们在多个信息存储库中自动搜索,将文件、数据与试验匹配,用比较简单的方法像注册试验的序列号,复杂一点的方法就是概率性的记录连接。
其次,我们收到一些结构数据的捐赠,捐赠这些数据的人是我们已经匹配好的,在此如果你有这方面的数据,我们也十分欢迎。
第三,我们允许任何用户对不完整的试验文件和数据进行递交,如果你发现你正在参与的试验需要这个,并有Patient Information Sheet的拷贝,那么你就可以上传了。
如果你有感兴趣的试验,并且知道在线的Clinical Study Report在哪里可以找到,那么你可以给我们链接。
坦白讲,我们不汇聚临床试验中患者层面的数据,因为这些数据涉及个人隐私,许多其他项目已经做过这个了,但是我们会把它引向做这类工作的人。
OpenTrials的理念
因为这是一个群策群力的项目,所以很值得谈谈它背后的理念。这是完全非商业的。Laura and John Arnold Foundation资助我们,有一个慷慨的顾问组,与Centre for Open Science一同建立Open Konwledge.
所有的数据都可以以“open data”共享,所以所有的东西都可随意使用,修改,以任何目的分享他人。我们不收取任何使用费,或是限制再使用。
我们希望在用我们数据的人也可以把他们的数据分享给我们。而且,任何帮助我们建立数据库的人都会得到奖励,无论是分享一个大的数据库还是上传一个单文件。
与此同时,我们也希望听到您的反馈。在我们建立的时候我们就发表了相关论文,因为我们非常需要在一步步中看到一些需求和反馈,当然我们也可以一直这样用着。
我们已经组织了一些用户参与的培训,并收到了非常有用的反馈,特别是在我们需要引进的其他文件类型和信息资源这方面。如果你认为我们可以做的更好,或者更多的信息我们需要去搜寻,那就请告诉我们吧。
